
안녕하세요. 개발하는 stocker입니다. 이전 시간에는 1일 봉 데이터를 준비하는 실습을 하였습니다. 1일 봉으로도 테스트할 수 있는 전략들이 있을 수 있지만 실제로 조금 더 정확한 테스트 혹은 시뮬레이션을 위해서는 최대한 짧은 단위의 봉 시세 데이터가 필요합니다. 그래서 이번에는 1분 봉 데이터를 준비해보는 시간을 가져보겠습니다.
이번 포스팅은 지난 번 포스팅에서 겹치는 내용을 몇몇 생략했습니다. 지난 번 포스팅을 먼저 보시고 이번 포스팅을 보시기를 추천합니다! 아래 링크로 들어시면 됩니다.!
https://dev-stocker.tistory.com/6
우선 아래 링크에서 과거 데이터를 가져옵니다. bitstamp에서 제공하는 ticker/USD 데이터입니다.
https://www.cryptodatadownload.com/data/bitstamp/

이번 시간에는 비트코인으로 분 봉 데이터를 준비해보도록 하겠습니다. 아래와 같이 다운을 받고 특정 폴더에 데이터를 모아둡니다. 분 봉은 일 봉과 달리 파일이 연도마다 분리됨을 알 수 있습니다. 그렇지만 일봉을 가져올 때와 비슷하게 접근하면 쉽게 파일을 만드실 수 있습니다.
해당 폴더에 작업할 파이썬(.py) 파일 혹은 주피터(.ipynb) 파일을 만들고 필요한 모듈을 불러옵니다. 이후에 pickle파일로 저장하기 위해 pickle도 임포트를 합니다.
import pandas as pd
import pickle
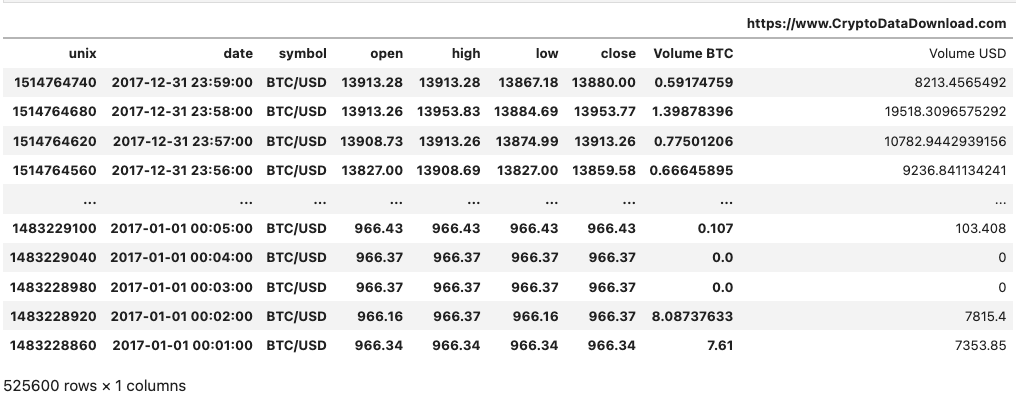
데이터를 살펴보면 지난 번 일봉와 비슷한 데이터를 볼 수 있습니다.
아래 코드를 실행하여 모든 파일의 row들을 list에 저장합니다.
row_list = list()
for year in [2017, 2018, 2019, 2020, 2021]:
df = pd.read_csv(f'Bitstamp_BTCUSD_{year}_minute.csv')
df = df.iloc[1:]
for row in df.itertuples():
data = [row[0][1], float(row[0][3]), float(row[0][4]), float(row[0][5]), float(row[0][6]), float(row[0][7])]
row_list.append(data)
리스트를 데이터 프레임으로 만듭니다.
columns = ['Datetime', 'Open', 'High', 'Low', 'Close', 'Volume']
total_df = pd.DataFrame(row_list, columns=columns)
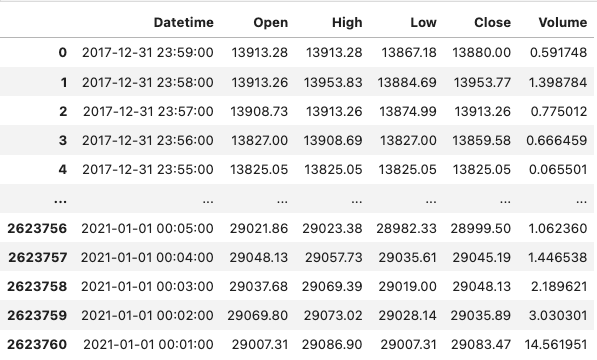
코드를 실행하면 다음과 같은 결과가 나옵니다. 오름차순도 내림차순도 아닌 이상한 형태로 정렬된 데이터들을 보실 수 있습니다.
그 다음 데이터를 Datetime을 기준으로 내림차순으로 정렬하고 인덱스 수정 및 Datetime 타입을 변경합니다.
total_df = pd.DataFrame(row_list, columns=columns)
total_df.sort_values(by='Datetime', axis=0, ascending=True, inplace=True)
total_df.set_index('Datetime', inplace =True)
total_df.index = pd.to_datetime(total_df.index, format='%Y-%m-%d %H:%M:%S')
total_df['Datetime'] = total_df.index
아래와 같이 깔끔하게 데이터가 나온 것을 알 수 있습니다.

마지막으로 결측값을 채우는 작업을 하겠습니다. 저는 비어 있는 분 봉 데이터를 찾아서 위아래 데이터로 채우는 식으로 결측값을 메꾸었스니다. 솔직하게 말씀드리자면 이 방법은 결측값이 많은 경우 그다지 좋은 방법이 아닙니다.
# 실제 분 봉 데이터의 처음 데이터와 끝 데이터 사이가 모두 채워진 분 데이터를 만든다.
temp_df = pd.DataFrame(pd.date_range(start=total_df.index[0], end=total_df.index[-1], freq='1min'))
# 분봉 데이터의 0번째 행의 이름을 Datetime으로 바꾼다.
temp_df.rename(columns={0: "Datetime"}, inplace=True)
# left join
total_df.index.name = None
total_df = pd.merge(left=temp_df, right=total_df, how="left", on='Datetime')
# 아래 위 데이터로 결측 값을 채운다.
total_df = total_df.fillna(method='ffill')
total_df = total_df.fillna(method='bfill')
아래 코드를 실행하여 결측 값이 있는지를 확인합니다.

마지막으로 완성한 데이터프레임을 pickle 파일로 저장하면 끝입니다.
total_df.to_pickle("btc_usd_1m.pkl")'트레이딩' 카테고리의 다른 글
| [트레이딩] 암호화폐 선물 시장에서 무위험 +a(약 10%) 수익 창출 꿀팁! (1) | 2022.12.23 |
|---|---|
| Funding Fee를 이용한 트레이딩 꿀팁 - SUN 토큰 (1) | 2022.07.24 |
| 암호화폐 시장의 Funding Fee(펀딩비)와 Funding Rate(펀딩 비율) 소개 및 분석 (2) | 2022.07.24 |
| [Python]백테스트를 위한 암호화폐 데이터 준비하기(1일 봉) (0) | 2022.02.24 |
| [Python]Binance 거래소 API 연동을 위한 ccxt 라이브러리 사용법 (0) | 2022.02.18 |



