안녕하세요 개발하는 stocker입니다. 시스템 트레이딩 전략을 개발하기 전에 백테스트를 하는 것은 기본 중 기본입니다. 백테스트를 위해서는 당연히 과거 데이터가 있어야겠죠?
이번에는 파이썬에서 백테스트를 하기 위해 필요한 데이터를 준비하는 실습을 진행하겠습니다.
가장 먼저 아래의 링크에서 과거 데이터를 가져옵니다! 저는 bitstamp에서 제공하는 ticker/USD 환율 데이터를 가져오고자 합니다!(여기가 긴 기간 동안의 데이터가 있어서 좋더라고요 ㅎㅎ) 아래의 빨간 글씨를 누르면 다운받으실 수 있습니다.
https://www.cryptodatadownload.com/data/bitstamp/

이번 실습에서는 이더리움 일 봉 데이터를 만들어 보겠습니다. 아래와 같이 다운을 받고 특정 폴더에 데이터를 모아 둡니다.

해당 폴더에 작업할 파이썬(.py) 파일 혹은 주피터(.ipynb) 파일을 만들고 필요한 모듈을 불러옵니다. 이후에 pickle파일로 저장하기 위해 pickle도 임포트를 합니다.
import pandas as pd
import pickle그리고 아래의 코드를 실행하여 csv로 되어 있는 이더리움 일 봉 데이터를 불러옵니다. 데이터를 불러오면 아래와 같이 (조금 이상한) 데이터프레임을 불러올 수 있습니다.

위 데이터에서 상단바에 해당하는 내용은 데이터프레임에서는 0번째 행으로 봐도 됩니다. 데이터를 가공하는 데에는 딱히 필요가 없으니 각 열에 위치하는 값만 기억해두고 첫 번째 행은 삭제합니다.
df = df[1:]
여기서 데이터프레임을 자세히 들여다보면 한 가지 이상한 부분을 알 수 있습니다. 열이 분리된 것처럼 보이지만 실제로는 하나의 열입니다. 하나의 열에 튜플 형태로 여러 개의 데이터가 들어가 있는 구조입니다.

만약 1번째 행의 1번째 열에 해당하는 데이터를 가져오려면 이렇게 가져오셔야 합니다.
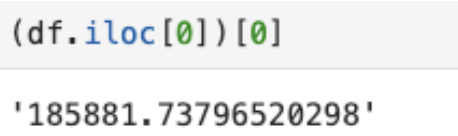
저는 이차원 데이터를 새로 만들어 다시 데이터프레임을 만드는 방법을 생각했습니다. 코드에서 for 반복문을 돌면서 실제로 필요한 데이터만 row로써 차곡차곡 이차원 리스트에 append 합니다.
data_list = list()
for data in df.itertuples():
row_list = [data[0][1], float(data[0][3]), float(data[0][4]), float(data[0][5]), float(data[0][6]), float(data[0][7])]
data_list.append(row_list)
위 코드를 실행하면 아래와 같은 리스트를 만드실 수 있습니다.

위 리스트를 사용하여 DataFrame을 만듭니다.
columns = ['Datetime', 'Open', 'High', 'Low', 'Close', 'Volume']
result_df = pd.DataFrame(data_list, columns=columns)

데이터를 보시면 어딘가 이상한 부분을 찾으실 수 있습니다. 가격이 0일 수는 없을 텐데 말이지..
가격 데이터에 0이 있는 행을 모두 삭제합니다.
result_df = result_df[(result_df['Open'] != 0.0) &
(result_df['High'] != 0.0) &
(result_df['Low'] != 0.0) &
(result_df['Close'] != 0.0)]
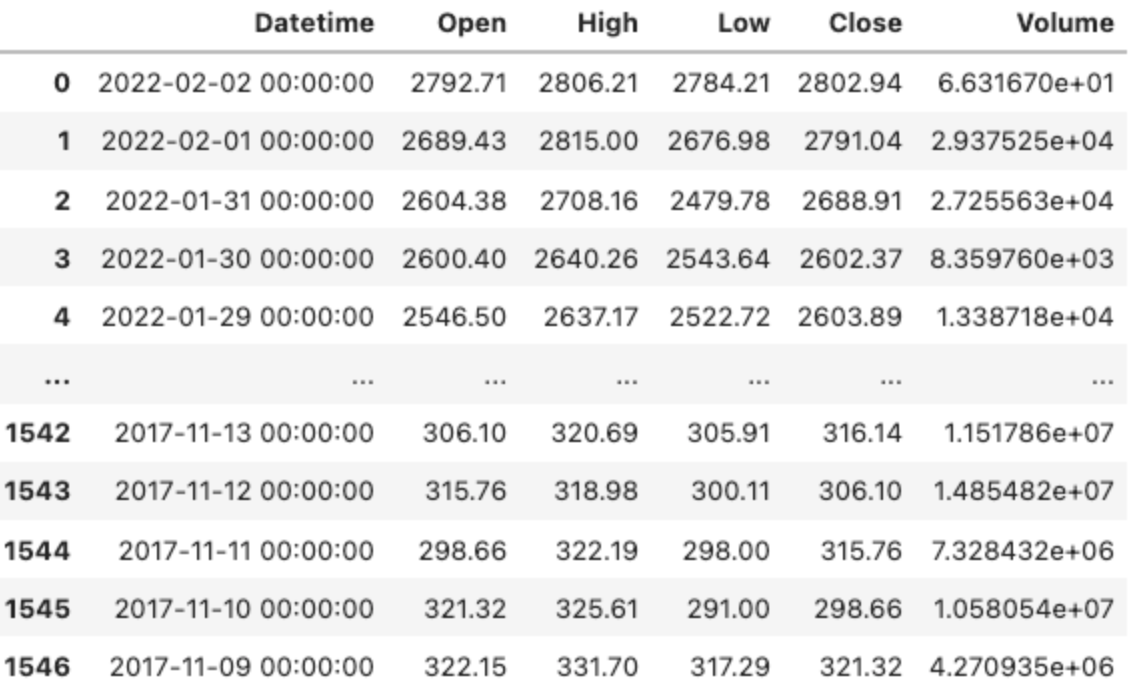
마지막으로 혹시나 데이터가 섞었을지도 모르니 정렬하고 Datetime 컬럼의 타입을 바꾸어 줍니다. 이제 마음에 드는 DataFrame이 완성되었습니다.
result_df.sort_values(by='Datetime', axis=0, ascending=True, inplace=True)
result_df.set_index('Datetime', inplace=True)
result_df.index = pd.to_datetime(result_df.index)
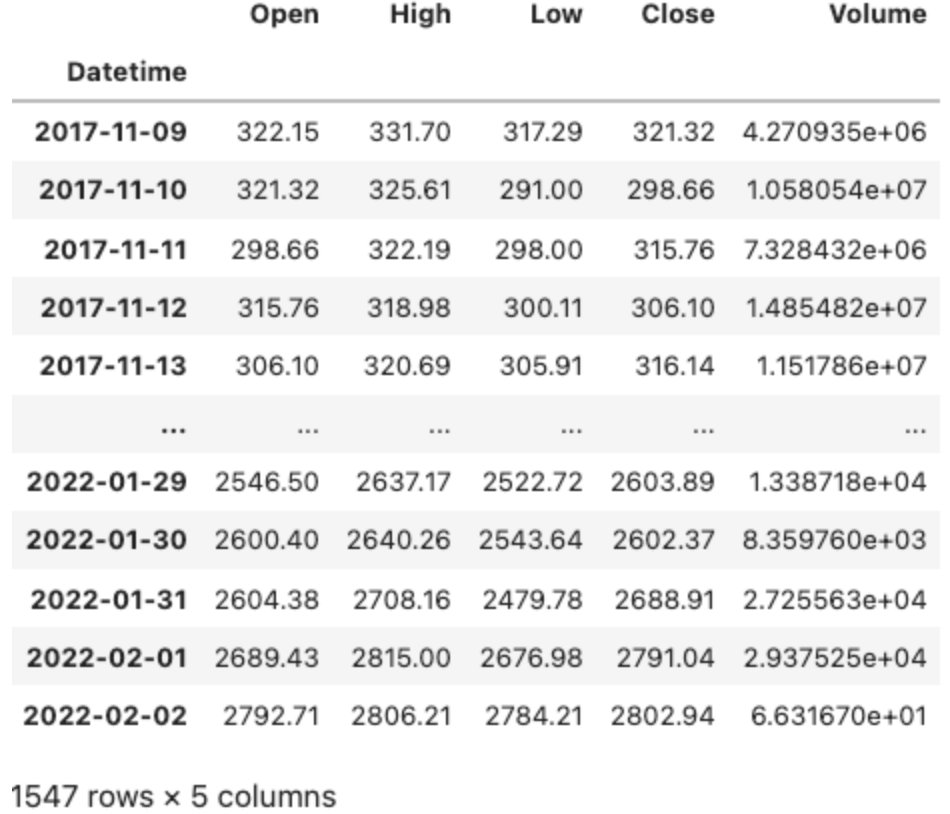
마지막으로 결측값(결측 날짜)가 있는지를 확인합니다. 아래의 코드에서 True가 나오면 모든 시간대의 값이 모두 들어있다는 의미이기에 결측값이 없다는 결론을 내실 수 있습니다.
date_range = pd.date_range(start='2017-11-09', end='2022-02-02')
list(date_range) == list(result_df.index)
마지막으로 pickle파일로 저장하면 백테스트를 위한 데이터 준비가 완성됩니다.
result_df.to_pickle('eth_usd_1d.pkl')
일련의 과정을 함수화하면 다음과 같습니다.
class NotMatchDatetimeException(Exception):
pass
def validate_datetime(df):
start = datetime.strftime(df.index[0], "%Y-%m-%d")
end = datetime.strftime(df.index[-1], "%Y-%m-%d")
date_range = pd.date_range(start=start, end=end)
t1 = date_range
t2 = df.index
if list(date_range) == list(df.index):
return True
return False
def transfer_bitstamp_1d_csv_to_pkl(file_path, upload_filename):
df = pd.read_csv(file_path)
data_list = list()
columns = ['Datetime', 'Open', 'High', 'Low', 'Close', 'Volume']
df = df[1:]
for data in df.itertuples():
row_list = [data[0][1], float(data[0][3]), float(data[0][4]), float(data[0][5]), float(data[0][6]), float(data[0][7])]
data_list.append(row_list)
result_df = pd.DataFrame(data_list, columns=columns)
result_df = result_df[(result_df['Open'] != 0.0) &
(result_df['High'] != 0.0) &
(result_df['Low'] != 0.0) &
(result_df['Close'] != 0.0)]
result_df.sort_values(by='Datetime', axis=0, ascending=True, inplace=True)
result_df.set_index('Datetime', inplace=True)
result_df.index = pd.to_datetime(result_df.index)
if not validate_datetime(result_df):
raise NotMatchDatetimeException
result_df.to_pickle(upload_filename)
return result_df
이상으로 포스팅을 마치겠습니다. 감사합니다! 질문이 있으시거나 지적할 사항이 있으시면 언제든 댓글 부탁드립니다!
'트레이딩' 카테고리의 다른 글
| [트레이딩] 암호화폐 선물 시장에서 무위험 +a(약 10%) 수익 창출 꿀팁! (1) | 2022.12.23 |
|---|---|
| Funding Fee를 이용한 트레이딩 꿀팁 - SUN 토큰 (1) | 2022.07.24 |
| 암호화폐 시장의 Funding Fee(펀딩비)와 Funding Rate(펀딩 비율) 소개 및 분석 (2) | 2022.07.24 |
| [Python]백테스트를 위한 암호화폐 데이터 준비하기(1분 봉) (0) | 2022.02.25 |
| [Python]Binance 거래소 API 연동을 위한 ccxt 라이브러리 사용법 (0) | 2022.02.18 |



